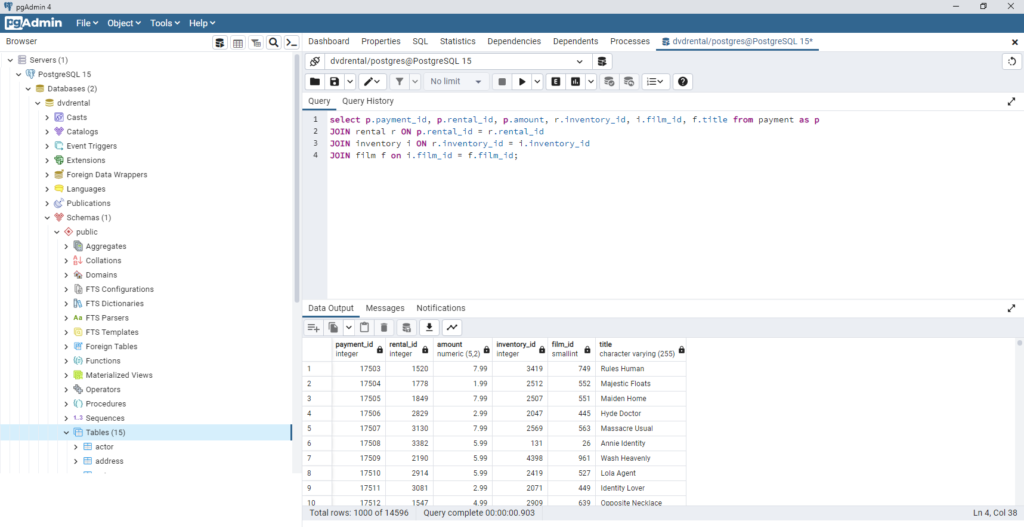
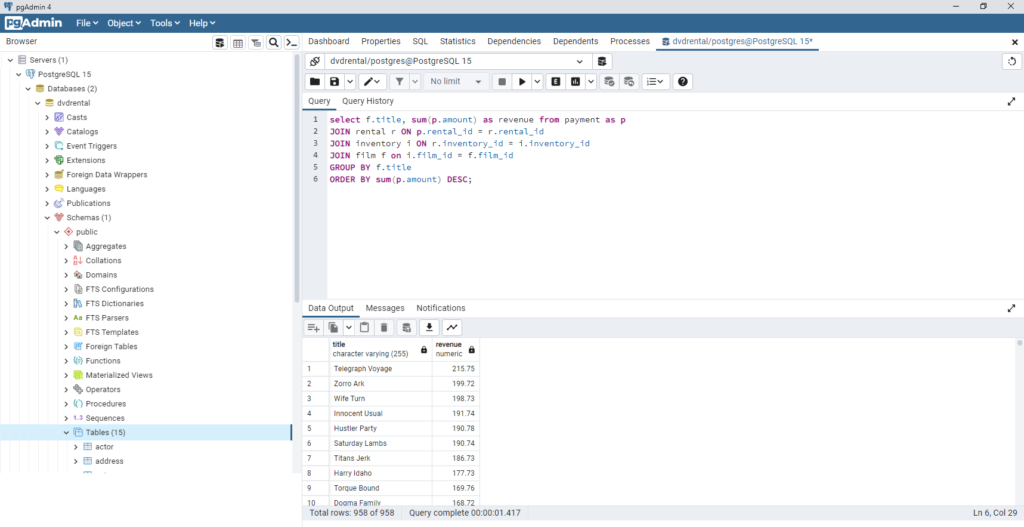
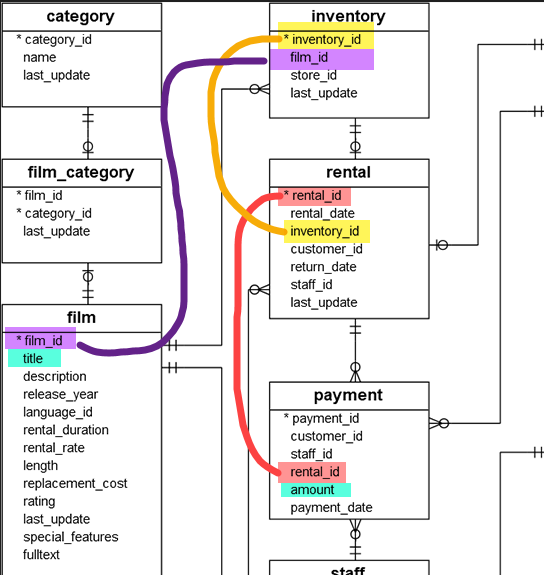
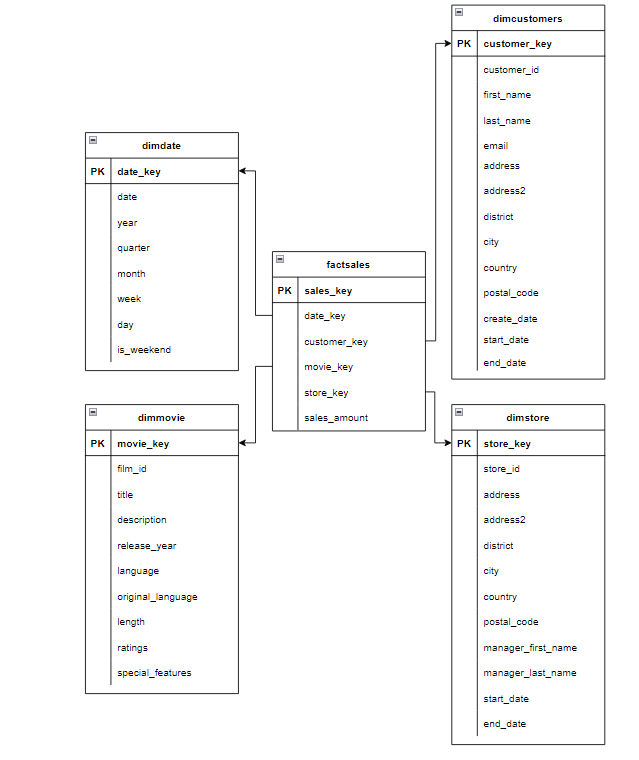
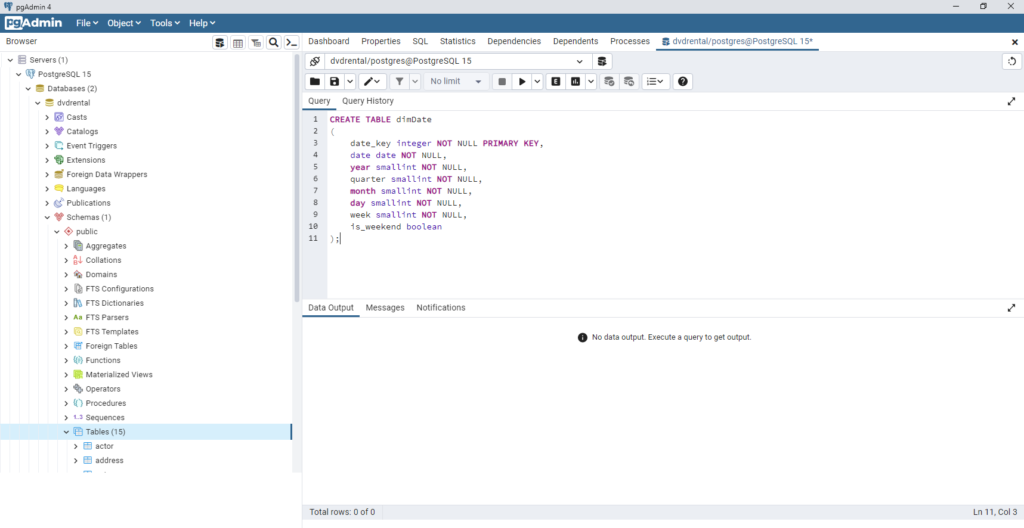
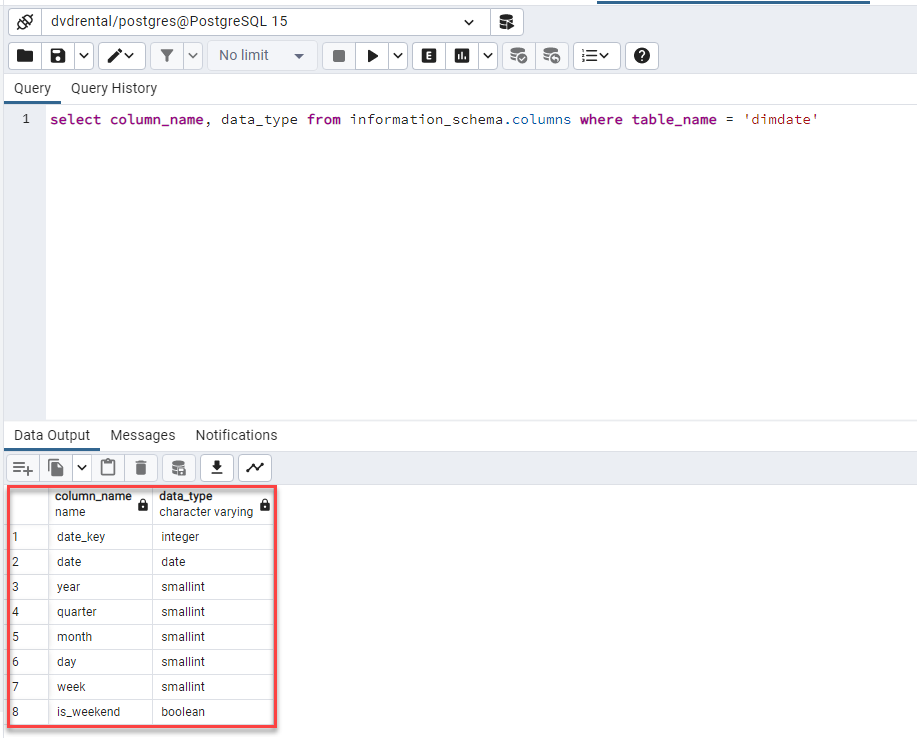
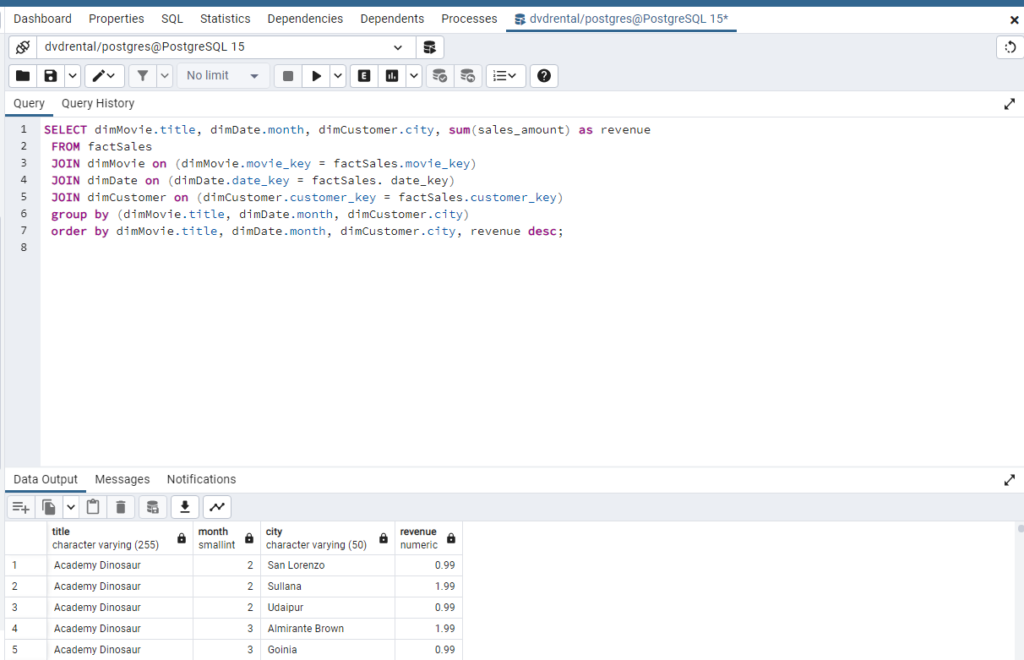
CREATE TABLE dimCustomer
(
customer_key SERIAL PRIMARY KEY,
customer_id smallint NOT NULL,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
email varchar(50),
address varchar(50) NOT NULL,
address2 varchar(50),
district varchar(20) NOT NULL,
city varchar(50) NOT NULL,
country varchar(50) NOT NULL,
postal_code varchar(10),
phone varchar(20)NOT NULL,
active smallint NOT NULL,
create_date timestamp NOT NULL
start_date date NOT NULL,
end_date date NOT NULL
);
CREATE TABLE dimMovie
(
movie_key SERIAL PRIMARY KEY,
film_id smallint NOT NULL,
title varchar(255) NOT NULL,
description text,
release_year year,
language varchar(20) NOT NULL,
original_language varchar(20),
rental_duration smallint NOT NULL,
length smallint NOT NULL,
rating varchar(5) NOT NULL,
special_features varchar(60) NOT NULL
);
Create TABLE dimStore
(
store_key SERIAL PRIMARY KEY,
store_id smallint NOT NULL,
address varchar(50) NOT NULL,
address2 varchar(50),
district varchar(20) NOT NULL,
city varchar(50) NOT NULL,
country varchar(50) NOT NULL,
postal_code varchar(10),
manager_first_name varchar(45) NOT NULL,
manager_last_name varchar(45) NOT NULL,
start_date date NOT NULL,
end_date date NOT NULL
);